What Happened with FPGA Acceleration?
In 2018, I took the jump from being primarily an FPGA hardware engineer to being primarily a software engineer. At the time, things were looking great for FPGA acceleration, with AWS and later Azure bringing in VMs with FPGAs and the two big FPGA vendors setting their sights on application acceleration. Almost 5 years later, I am working on another project with FPGAs, this time a cloud-oriented one. That has inspired me to write a retrospective on the last 5 years of what we thought would be an FPGA acceleration boom.
In 2016-2018, the major FPGA manufacturers have made great overtures about the applicability of FPGAs to compute acceleration, setting their sights on GPUs. Finally, the FPGA would be today's compute accelerator, not tomorrow's. Reality has worked out a bit differently. In 2022, FPGAs are still considered niche devices, but they have made great strides since then. In order to make the jump from niche to mainstream, there is a lot of work still to be done.
Background: What is an FPGA?
A Field Programmable Gate Array (FPGA) is a device that can emulate digital circuits. Instead of having large processing units, they have millions of small lookup tables, which can compute simple logical functions. The lookup tables are combined together using a routing network on the FPGA to create larger circuits within the logic fabric of the FPGA. Registers within the FPGA fabric allow those circuits to be pipelined, and most FPGAs today also contain hardware multipliers and RAM blocks, since those are hard to emulate with lookup tables. FPGAs also offer clocking circuits to support these applications, and both programmable I/O pins (for things like blinking lights) and fixed-function I/O units (for protocols like PCIe or DDR4) to allow the FPGA to interact with the outside world.
An example diagram of an Intel FPGA is below:
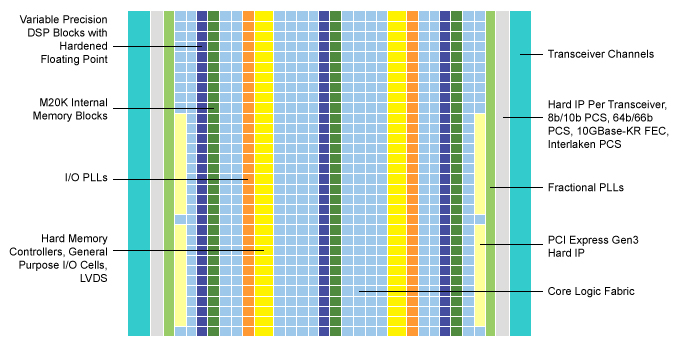
The Arria 10 device shown is typical of a modern FPGA in its structure. It has all the bells and whistles to implement a high-performance application.
Keep in mind that these FPGAs are big devices. In fact, they are generally the biggest logic devices that you can buy. As of today, an FPGA, the Xilinx Versal VP1802, the largest FPGA available, has 92 billion transistors, while the Nvidia GH100, the largest GPU, has 80 billion. Currently, Apple's M1 Ultra is the only computing chip (CPU, GPU, or FPGA) that beats the FPGAs for transistor count, at 114 billion, and combines a huge CPU and a huge GPU (techically, the Cerebras Wafer Scale Engine is also a chip with more transistors).
However, FPGAs are completely proprietary. Despite the similarity between architectures from FPGA vendors, they do not open up anything about their architectures. Currently, there are two major FPGA vendors, Intel and AMD, but the situation is nothing like x86. There are no inter-operable standards.
FPGA Programming
Throughout the history of FPGAs, the primary programming languages used for them have been hardware description languages (HDLs), like Verilog and VHDL. Hardware description languages are designed to describe hardware with a great deal of precision, and as much expressiveness that can come afterwards. Hardware description languages are used to produce configurations for FPGAs using a process that is called synthesis. Instead of an executable or .elf file, the configuration is described by a proprietary bitstream. Everything about the process is proprietary to the vendors.
Hardware description languages are generally fairly primitive from the perspective of programming language theory. It is possible to write valid things in a hardware description language that cannot synthesize to hardware, and there is very little possibility of using programming concepts like inheritance in hardware description languages. Even recursion needed until 2008 to make it into Verilog hardware descriptions.
FPGA synthesis is several orders of magnitude more complicated than a traditional compilation process, and involves approximating many NP-hard problems with millions of elements. As a result, synthesis of an FPGA design can take several hours on a large server.
The Promise of Accessible FPGAs
Around 2015, the two FPGA giants, Altera (now Intel) and Xilinx (now owned by AMD) invested heavily in the idea of computational acceleration. At the time, things looked great for FPGAs as computing devices. Despite the expense, the largest FPGAs at the time could out-FLOP the largest GPUs in some applications, despite not having the benefit of hard floating point units. On integer tasks, there was no contest: a small FPGA could out-perform the largest GPUs on string parsing and other tasks that were not floating-point-specific. On top of that, the FPGA would consume less than 1/5th the power of a GPU or CPU performing a comparable task.
To support their acceleration ambitions, Xilinx and Intel started selling FPGA cards designed for application acceleration. These cards were cheaper than FPGA cards for other purposes (about in line with a server GPU, not 10x more expensive) and were designed so that you didn't need to be a hardware engineering expert to understand how to use them. Amazon and Microsoft also noticed the promise of FPGAs for compute acceleration. Microsoft in particular used an FPGA system to accelerate Bing, and reportedly uses FPGAs in Azure servers to accelerate networking.
Both Amazon and Microsoft offer instances with FPGA cards to allow cloud customers to use FPGA acceleration. With new cards aimed at server deployment and support from the top two cloud companies, FPGA acceleration looked like it was in a good place to take off.
Just One Problem...
Meanwhile, FPGAs had a huge problem: the way you design a custom circuit is very different than the way you program a processor. Exotic DSPs, one-penny microcontrollers, massive GPUs, and server CPUs all have similar, mature toolchains. FPGAs don't. The steps to program an exotic, proprietary DSP are almost the same as the steps to program for an x86 CPU. Not so for an FPGA. The toolchains for GPUs and CPUs use many common open-source components. FPGA toolchains don't have anything in common with each other.
It seems only natural that around that time, Altera and Xilinx would invest heavily in technologies that closed the gap between software code and FPGA hardware. The technology that they mainly chose was high-level synthesis (HLS), which would add a few more steps to the synthesis flow to allow hardware to be described in C or C++. C++ code describing a data flow would be synthesized to a series of hardware blocks with standardized interfaces between them.
High-level synthesis has been around for a while: Since the early 2000's, Matlab has offered HLS for signal processing applications. However, before the late 2010's, there weren't any successful attempts to make a general-purpose HLS system. This was the challenge that Altera and Xilinx now faced. Software engineers would find many different applications, and the new HLS system would need to work for all of them.
Pursuing General-purpose High-level Synthesis
Altera began its general-purpose HLS efforts by supproting OpenCL on its FPGAs. The OpenCL framework allowed FPGAs to work with a common acceleration framework that could also be used for GPUs. However, it also coerced the FPGA application to use an architecture that looked like a GPU. This is fine for most acceleration tasks, but takes a lot of the magic of FPGAs off the table. To compensate for this, Altera and later Intel added FPGA-specific OpenCL features. For example, streaming data from one hardware block to another (instead of through memory) required using "streams" which were Intel-specific.
Xilinx's first major HLS effort was built inside its Vivado design suite. Vivado HLS didn't use a framework like OpenCL, and instead allowed you to create hardware modules with C++ code. Chip architecture still had to be done like hardware, although Vivado allows you to do it with block diagrams.
Both general-purpose HLS systems have a problem: #pragma statements. HLS
code tends to feature almost as many lines of pragmas as lines of code. Worse, the pragmas control
things like insertion of pipeline stages, loop unrolling, and other tasks that expose the nature of
the hardware to the engineer. Combined with the FPGA-specific constructs, pragmas have pretty much
squashed the dream that FPGA programming might be accessible to software engineers.
Each of the two major vendors later copied each other's approach: Intel introduced an HLS compiler to compete with Xilinx, and Xilinx added an OpenCL environment. At best, these HLS systems have become productivity tools for hardware engineers rather than allowing software engineers to access FPGAs. They are not the "CUDA" of FPGAs.
An Early Foothold: Neural Networks
Neural networks also offered another foothold through which FPGAs could become more mainstream. FPGAs particularly promised benefits on neural network inference, where they could offer huge SRAM bandwidth and thousands of integer ops per clock cycle. The FPGA companies and their partners recognized this, and began working on compilers for neural network inference on FPGAs. These efforts were wildly successful.
However, FPGAs have faced and continue to face stiff competition in machine learning inference. Several companies during the same time frame have successfully developed inference ASICs, NVidia released inference-focused GPUs, and the AVX-512 and VNNI instruction sets from Intel have helped to improve neural network inference performance on CPUs. FPGAs in machine learning applications now have to justify their cost compared to both dedicated hardware and devices that are more general-purpose.
Moving Past General-Purpose HLS
In 2019, Xilinx released Vitis, a platform for HLS and development of hardware accelerators. Vitis introduced the approach of hardware-accelerating several common software libraries, including FFmpeg, TensorFlow, BLAS, and OpenCV. Additionally, Vitis can be used for HLS of C++ and Matlab, along with synthesis of P4 packet processing programs.
The Vitis suite appears to be a concession to the idea that a general-purpose HLS system wouldn't work for FPGAs accelerators. Instead, Vitis is a suite of special-purpose compilers. This approach appears to be working: it has resulted in FPGAs expanding to many important niches.
FPGA Acceleration Hits
Other than machine learning acceleration, there have been many successes of FPGA acceleration that leverage the unique benefits of FPGAs. However, these accelerators haven't necessarily benefitted from high-level synthesis the way that the FPGA companies hoped.
High-frequency Trading
FPGA acceleration in high-frequency trading began long before 2016. FPGAs offered a unique value proposition for HFTs, since they allow you to respond to an incoming message with extremely low latency. Software packet processing relies on doing one step at a time: receiving a packet in full, parsing it, and generating a response. FPGAs allowed the HFT industry to do that in a streaming fashion. As a result, today's HFTs can execute trades in tens of nanoseconds, 100x better than the fastest software solutions, which needed microseconds.
Since HFT happens in nanoseconds, there isn't really much room for HLS systems. Reportedly, some HFT companies have invested in domain-specific HLS systems, but they have kept very quiet on any successes.
The HFT companies have one major advantage that I have not seen anywhere else in the FPGA industry: they treat FPGA hardware like software. It is software - you are not spending $10 million making a run of chips, you are just reprogramming something. However, applying software engineering methodologies and a software engineering mindset has allowed these companies to be more agile with FPGAs than everyone else. Traditional FPGA companies can likely learn a lot from this process.
SmartNICs
FPGA-enabled SmartNICs have helped Microsoft build Azure, and Intel and Altera are both investing heavily in SmartNICs. Reportedly, some of the Chinese clouds also use a similar approach to Azure, using an FPGA to accelerate virtualized networking.
In the case of SmartNICs and network acceleration, the throughput offered by building a wide pipeline on an FPGA is hard to match. Combined with the fact that the FPGA is programmable, and is not constrained by a limited instruction set the way that other packet-processing accelerators are. A traditional CPU just cannot reach 100 gbps at the same latency that it gets at 1 gbps, and an FPGA can do that (comparatively) easily.
SmartNICs benefit from P4 acceleration pipelines, and may be a platform for high-level synthesis of other domain-specific packet processing paths. I am not currently aware of an HLS system for eBPF programs, but that may be a promising solution for more flexible systems.
Computational Genomics
Computational genomics is one application where FPGAs appear to have won. Companies like Gemalto and Deneb Genetics offer solutions for genome processing on FPGAs. As a non-expert, computational genomics appears to be driven by the ability to make thousands of comparisons at the same time. This lends itself nicely to FPGAs, which can be turned into large banks of comparators.
As far as I am aware, many computational genomics systems don't use HLS any more, but may have started in OpenCL.
The Best is (Hopefully) Yet to Come
Domain-specific acceleration offers a lot of promise for FPGAs, but will never have a flashy "CUDA" moment. As of today, the FPGA companies appear to have made their peace with that. Still, there is tremendous promise for FPGAs, particularly accelerating network and storage applications in the coming years.
A New Development Paradigm
Languages like HardCaml, Chisel, and Bluespec promise to close the productivity gap between high-level languages and HDLs. Unlike we thought in 2016, the future of FPGA acceleration may not be in the hands of software engineers. It may come from hardware engineers, in which case it will come from closing the productivity gaps between hardware and software development, and learning to treat FPGA programming with the same mindset that we use for software code.
This is the same paradigm shift that happened to software in the 1980-90s. It took a long time: the first processors came out in the 1950s, and it took 30-40 years to invent the "software mindset." FPGAs are a more recent invention, with the first ones being made in the 1990s, and there are still a lot of kinks to work out.
The Elephant in the Room: Access
FPGAs have one big problem still compared to GPUs and CPUs, and this is a problem that has not gotten better over their history: FPGAs are expensive and hard to access.
FPGA accelerator cards cost thousands of dollars. I first wrote CUDA using my $200 home GPU. Many of us did our first programming on devices that we use every day. A Xilinx Alveo card costs over $3,000 today. It needs a $3,000 tool suite to program. This takes FPGA acceleration out of the range where an everyday hobbyist can experiment with it. Most FPGA programmers today learned how to program an FPGA by doing research or a course in college, run by the electrical engineering department. There is none of the same organic experimentation that we get in software.
Further, cheap FPGA boards and small FPGAs today are aimed at hardware engineers who want to build a thing, not software engineers who want to try acceleration. This is a totally different problem for a totally different group of people!
A final obstacle is that high-quality open-source code for FPGAs is almost non-existent, and there isn't a "Linux" of hardware or a standard library. Components like ethernet I/O cores cost tens of thousands of dollars and often contain bugs. The lack of these libraries and examples means that there isn't a good way to do FPGA accelerator development without significant investment in "boilerplate" technologies.
Open source and standardization would likely help on all fronts here. The economists who are in control at Xilinx and Intel are probably right that standardization and open sourcing key technologies will hurt them in the short term. Despite this, it may be key to the long-term success of the FPGA market in computing.
Until FPGA vendors can improve access to acceleration-ready devices and the toolchains and libraries that can be used to program them, they may be stuck as "the accelerators of tomorrow."
Epilogue: My Own Use of HLS
In 2015, I spent a few weeks looking at Altera's OpenCL system. I was very bullish on the technology, but it wasn't quite mature enough at the time and didn't match the use case.
More recently, I have been trying to figure out Xilinx HLS for my current FPGA project, hoping it
will save some work and help me generate good hardware quickly, but I am going back to SystemVerilog
in defeat. Learing the toolchain and the language of pragmas just wasn't worth it.